
C语言的随机函数 rand(), 理论上会在[1, RAND_MAX]之间生成均匀的随机数。但通常情况下,我们需要一个范围很小的随机数(例如随机化快排)。
多数人的做法(包括之前的我),直接采用 rand() % N 的做法。但根据 C-faq 13.15 的介绍,这并不是一个好方法。相比之下,提供了另外两种方案:
(int)((double)rand() / ((double)RAND_MAX + 1) * N)rand() / (RAND_MAX / N + 1)
为了验证哪种方式生成的随机数更均匀,我就打算做一个小小的测试。
实验步骤:
- 使用
rand()生成 10^7 个随机数。 - 对于每个随机数,分别带入3个函数中来生成随机数,并将结果输出到文件中。
- 使用R语言,利用
hist(x, breaks=range)来生成图像(感谢SHLUG上的朋友们)。
注:使用 rand()%N 方案生成的随机数被存储到了向量 r0 中,另外两种被存储到了 r1 和 r2 中。经过测试, r1 与 r2 绝大多数元素都是一样的。所以,接下来我仅对比 r0 和 r1
我把范围设到了5000,最后统计的结果让我很震惊:r0 和 r1 的频率分布都很均匀
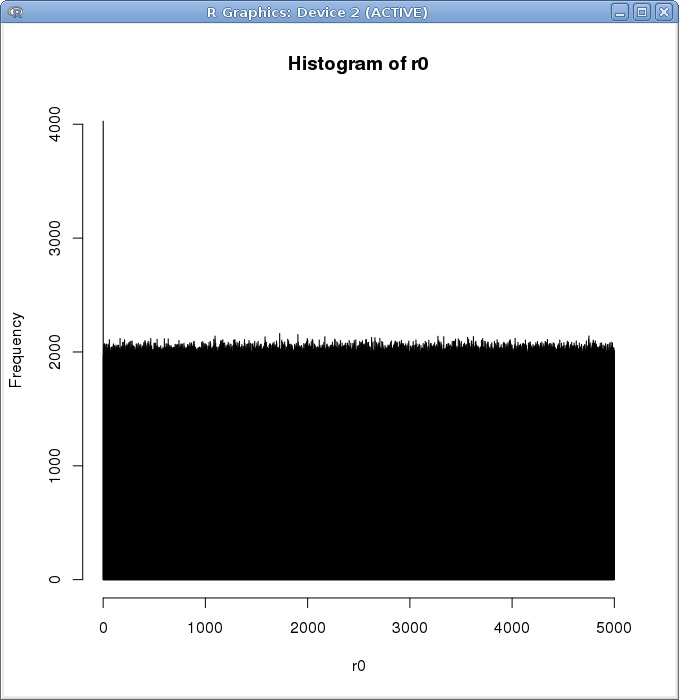
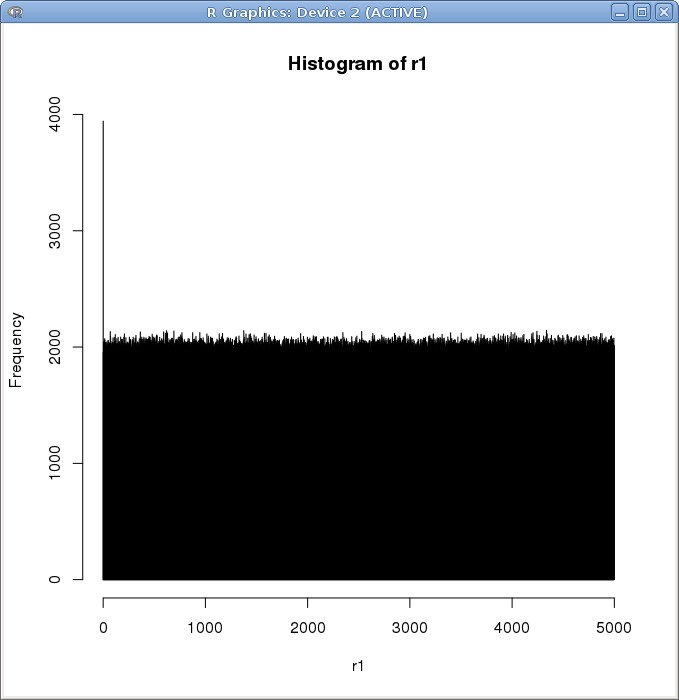
考虑到可能由于数据量太大抹掉了一些区别,我将数据范围缩减至 10^4
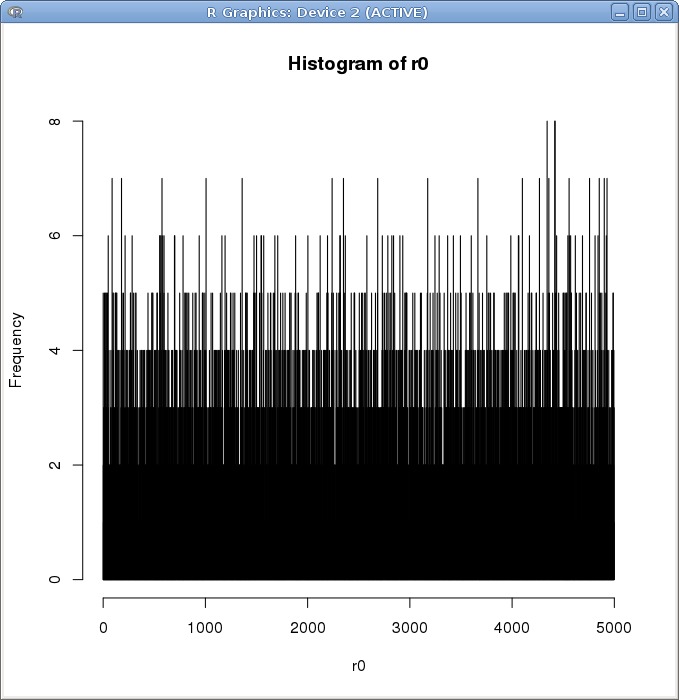
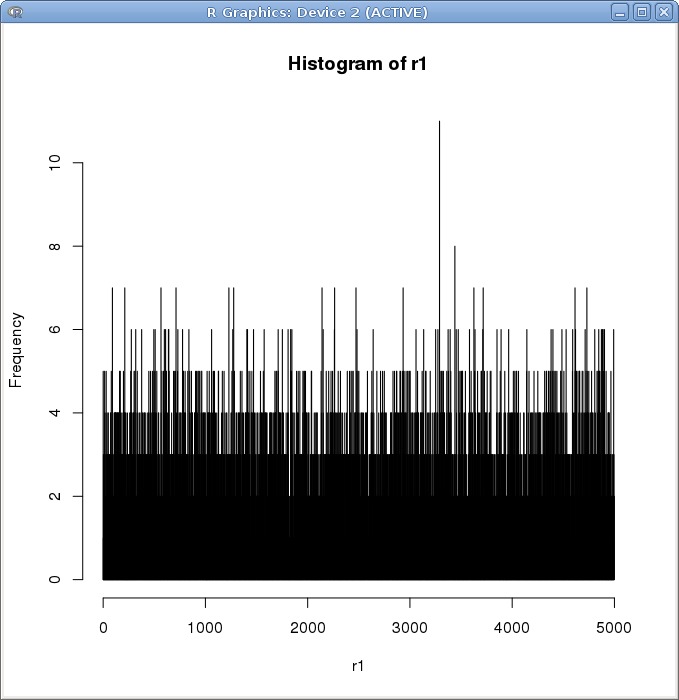
依旧看不到明显的区别。
我将随机数范围缩减到 [0,100)
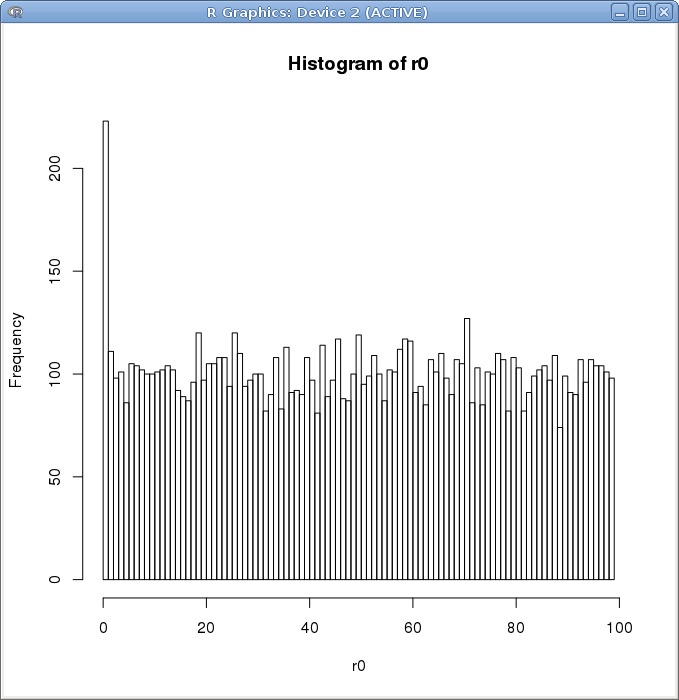
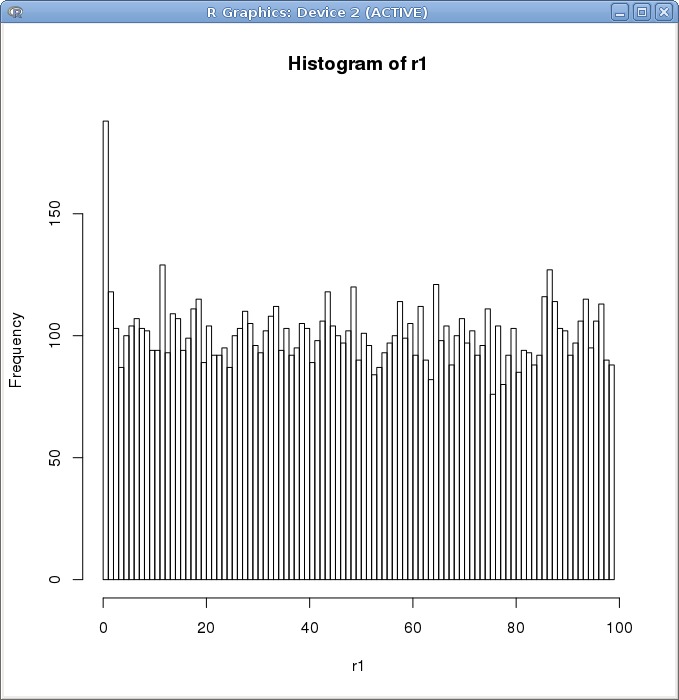
直观上看,仍然没有本质上的区别。
在 C-faq 13.18 上提到,使用 rand() % N 会让随机数具有周期性。但是我将范围设置为2,也没有找到明显的周期。
由此看来,rand() % N 并没有 显著 的缺陷。但为什么除了 C-FAQ,C语言的科学与艺术 也这么说呢?看来,找寻答案的道路还很漫长啊。
折腾这么久得到这样的一个结论,实在是太让人沮丧了。。。